They come from economic trade-offs. You are better off looking for special causes only after rejecting the possibility that results were due to normal system variation. If you mistakenly pursue a special cause when in reality the results were due to random luck, then you will damage your system and cause overall performance to decline!
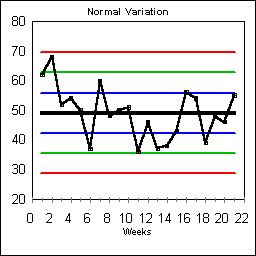
| Upper Control Line = 69-------
Upper Warning Line = 63----- Upper One-Sigma Line = 56--- Central Tendency = 49-- Lower One-Sigma Line = 42--- Lower Warning Line = 35----- Lower Control Line = 29------ Apply the rules to our data. Did an error spike of 65 indicate something special was occurring? [Hint: Look at Rule #1 in the right hand column, and then look for the Upper Control Line above.] Do you see how to change sigma into control lines and warning lines? [Hint: compare this page to the previous page.] |
EIGHT RULES FOR IDENTIFYING SPECIALNESS
1. Any values outside the control lines. Freak value 2. Two out of three points in a row in the region beyond a single warning line. Freak value
3. Six points in a row steadily increasing or decreasing. Process shift
4. Nine points in a row on just one side of the central tendency. Process shift
5. Four out of five points in a row in the region beyond a single one-sigma line.Process shift
6. Fourteen points in a row which alternate directions. Shift work or overcorrection 7. Fifteen points in a row within the region bounded by plus or minus one sigma. Garbage data or overcorrection
8. Eight points in a row all outside the region bounded by plus or minus one sigma. Garbage data or overcorrection |
|
The black horizontal center line is the average number of errors per week, 49.
The blue lines are One-Sigma Lines at 42 and 56. One-third of the time errors will fall outside the two One-Sigma Lines even though nothing special is occurring. The green lines are two-sigma Warning Lines at 35 and 63. About one in twenty-times, the errors will be above or below the Warning Lines even though the system has remained stable. The red lines are three sigma Control Lines at 29 and 69. One in four-hundred times, results will fall outside the Control Lines even though nothing special is in need of fixing. |
Each week, you should record the weekly error rate in your SPC chart. You
will instantly know whether the results warrant searching for a special cause. More importantly, you will instantly know if the results are telling you to BE
MORE PATIENT and gather more data before acting.
|
What do I do when the errors spike to 65 and you tell me nothing special is going on? |
If the 65 errors were normal system variation, then
next week, the system will tend back towards its
normal 49 errors per week
You can work on improving the system, but don't bother looking for an easy "fix." That could backfire on you. If you again get 65 errors, then Rule #2 will tell you that something special is happening and you best take a close look for something that has gone "out of whack". |
When nothing "special" needs fixing, then redesign the system so that anyone working in it will make fewer errors.
There are fourteen principles for improving systems described in our book, Principles For Improving Systems | KEY PRINCIPLES
|
When looking for a "special" cause of problems, become a detective and use the sleuthing skills of any good "Who done it?"
|
What do special causes look like? |
We've all been trained through schooling and life to deal with special causes. Look for differences in when things occurred, what occurred, how things occurred, where events happened, and who was working. When something breaks, there is frequently a special cause.
Special causes require special fixes. Sometimes, they fix themselves if the problem was simply someone was out sick. |
You are better off erring on the side of blaming the system than erring on the side of blaming a special cause.
What's so bad
about falsely
blaming a special
cause when an
error spike was
simply normal
variation? If an error spike was simply due to bad luck, then results would improve even if you didn't do anything. When you falsely blame a special cause, you will mistakenly believe that your actions caused the improvement. Not only
would you have fixed someone who wasn't at fault, but
you would have mislearned what needed to be done the next time errors spike.
Other "fixes" might be changes in equipment,
training, or staffing levels. No matter what the "fix",
you will fool yourself into thinking you made things
better without realizing the improvement was simply
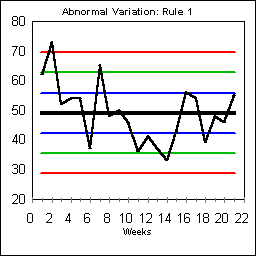
part of normal variation. ABNORMAL VARIATION: RULE #1
Rule #1 is the simplest of all rules. Any data points outside the control lines are considered "special." These points are sometimes called "freak values" indicating something special happened, but then returned to normal.
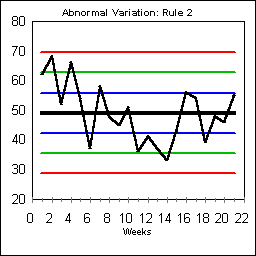
ABNORMAL VARIATION: RULE #2
Rule #2 is an early detector of "specialness". It looks for two out of three points in a row in the region beyond a single warning line. This run begins on Day 2. Usually Rule #2 like Rule #1 also indicates some freak "special" values, but it also might indicate a process shift that is permanent.
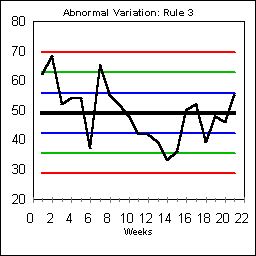
ABNORMAL VARIATION: RULE #3
Rule #3 recognizes trends by looking for six points steadily increasing or decreasing.
On this chart, the downward trend begins on day 7 and continues through day 14. Days 11 and 12 had the same value of 42. Simply skip days that are exactly the same in your count. This trend had statistical significance as of day 13. Rule #3 usually indicates a process shift rather some temporary "special" values.
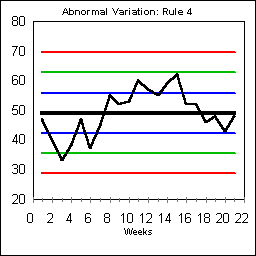
ABNORMAL VARIATION: RULE #4
Rule #4 recognizes trends by looking for nine points in a row on just one side of the central tendency.
On this chart, beginning on day 8, the data points start a lengthy run above the central tendency. Skip any days that land exactly on the Central Tendency. Rule #4 like Rule #3 usually indicates a basic process shift.
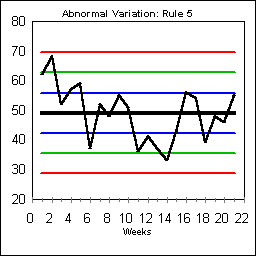
ABNORMAL VARIATION: RULE #5 Rule 5 looks for four out of five points in a row in the region beyond a single one-sigma line. This rule recognizes that it is abnormal for too many data points to be outside the normal plus and minus one-sigma range around the central tendency. This Rule is triggered by the data beginning on Day 11. Typically a process shift will trigger Rule 5.
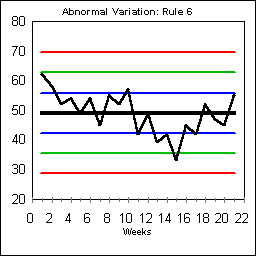
ABNORMAL VARIATION: RULE #6
Rule #6 looks for fourteen points in a row which alternate directions. This kind of flipping back and forth is usually an indication of shift work, alternating schedules of some sort, or overcorrection that is causing results to bounce from one over-corrected direction to another.
On this chart, the alternating pattern begins on Day #2, but doesn't become statistically significant until Day #15.
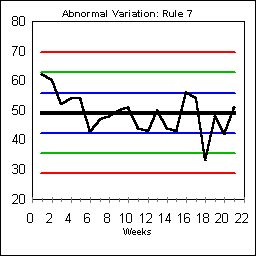
ABNORMAL VARIATION: RULE #7
Rule 7 looks for fifteen points in a row within the region bounded by plus or minus one sigma. The rule is based on the recognition that normal variation includes some results that will be fairly far away from the central tendency.
Sometimes Rule 7 indicates garbage-data which has been "corrected" to make people look better. From a worker perspective if people in the past had been falsely blamed for bad results, then it would be natural to protect themselves from bosses who truly don't understand variation. Rule 7 should not be used as an excuse to attack the workers who gathering data. Instead, it should be recognized as a system in which fear may be too prevalent. ABNORMAL VARIATION: RULE #8
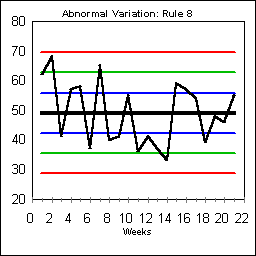
Rule 8 looks for eight points in a row all outside the region bounded by plus or minus one sigma. Rule 8 is triggered by the run beginning on Day 4. Usually this rule indicates garbage data or serious overcorrection from subgroup to subgroup if the data points are bouncing between extremes.
All Statistical Process Control (SPC) charts are used to help identify when something special is going on. Depending on the kind of data used, different SPC charts are chosen
How do I track
something like
total sales by my
sales agents?
How do I track the
amount of time it
takes to complete a
task? There are three basic groups of SPC charts that will cover most situations.
1. Proportion Charts: Chapter 2 2. Unit Charts: Chapter 3 3. Averages and Range Charts: Chapter 4
Imagine "fixing" an employee you thought was the
special cause when in reality the error spike was
simply normal variation.
How do I track
something like
percent of phone
calls answered
within three rings?
You are now ready to move on to the nitty gritty details of how to construct each of the above SPC charts.
Chapter
One
Chapter
Two
Chapter
Three
Chapter
Four
References and
Photocopying Rights
Top of page
Home Page
Resource Links
Sounding Board
Books